IEEE TRANSACTIONS ON MULTIMEDIA
Authors: Weizhi Nie、Jeff、Rihao Chang、Lei Qu、An-An Liu
Slides: PDF
Abstract
Three-dimensional reconstruction is a multimedia technology widely used in computer-aided modeling and 3D animation. Nevertheless, it is still hard for reconstruction methods to overcome the 3D geometry missing and the object occlusion in the single-view images. In this paper, we propose a novel method(CPG3D) for reconstructing high-quality 3D shapes from a single image under the guidance of prior knowledge. Using the single-view image as the query, prior knowledge is collected from public 3D datasets, which can compensate for missing 3D geometries and assist the 3D reconstruction network to high fidelity results. Our method consists of three parts: 1) Cross-modal 3D shape retrieval module: This part retrieves related 3D shapes based on 2D images. Here, we apply the pre-trained model to guarantee the correlation between the retrieved 3D shape and the input image. 2) Multimodal information fusion module: We propose a multimodal attention mechanism to handle the information fusing of 2D visual and 3D structural information; 3) Three-dimensional reconstruction module: We propose a novel encoder-decoder network for 3D shape reconstruction. Specifically, we employ the skip connection operation to link the target image’s visual information with the 3D model’s structural information to enhance the prediction of 3D details. During training, we employ two carefully designed loss functions to lead the multimodal learning to obtain proper modal features. On the ShapeNet and Pix3D datasets, the final experimental results reveal that our method notably increases reconstruction quality and outperforms SOTA methods.
Introduction
Three-dimensional object reconstruction from a single-view RGB image is a widely researched multimedia task. It has been already applied in computer-assisted modeling,3D animation, and robot localization. Unlike humans, who can easily infer the 3D shape of an object from a single image due to previously learned knowledge and an innate ability for visual understanding, computer vision systems are unable to directly reconstruct the 3D shapes from a single image because of the lack of structural information. Hence, the assistance of shape priors and the ability of shape reasoning play an indispensable and important role in 3D object reconstruction.
Related Work
Lots of single-view 3D object reconstruction methods rely on the massive training on large-scale datasets, which maps 2D image features into the 3D shape feature space through convolutional neural networks. However, this learning manner constrains their reconstruction ability due to the information loss in the single-view image. Although these methods have achieved some promising results on the views of 3D objects with clean backgrounds, they still fail to produce credible reconstruction results on views with complex backdrops, such as occlusion and truncation. This condition presents a new challenge to single-view 3D object reconstruction.
Motivation
Prior knowledge is an effective form to compensate for the 3D geometry loss, which provides the network with multimodal input for a comprehensive understanding of the target object. Consequently, the pipeline of prior-guided 3D reconstruction can be redesigned as: given a single-view image, computer vision systems should be able to automatically associate the shape prior knowledge and utilize this prior knowledge to guide the shape reconstruction. Thus, in this paper, single-view reconstruction is divided into two tasks.
- Obtaining the prior knowledge from the target image: Humans proactively learn the knowledge and memorize it as priors, while computers similarly obtain their priors from memory units. Therefore, this task constructs prior memories and retrieves the desired knowledge.
- Reconstructing high quality 3D shapes under the guidance of prior knowledge: Humans can infer the 3D structure of objects depicted in images based solely on prior knowledge.
In a similar approach, computers should combine previously acquired priors with image data and infer the desired shape in a learnable manner. Consequently, this paper focuses on efficient methods of information integration and shape reconstruction from the integrated features.
Contributions
The main contributions of our work are as follows:
- We propose a novel approach for reconstructing high quality 3D shapes based on a given single-view image and its retrieved 3D prior knowledge. Shape priors can effectively compensate for the unseen structures in single-view images and optimize the performance of reconstruction.
- We propose a novel multimodal knowledge fusion network based on the cross attention mechanism, which can hierarchically fuse the image’s visual information with relevant 3D shape structural information.
- We propose a three-dimensional reconstruction network assisted by the skip connections from image features. Besides, we validate the performance of the proposed method on the ShapeNet and Pix3D datasets. Several ablation studies are conducted to evaluate the effectiveness of each module. All experiments demonstrated the superiority and reasonableness of our network design.
Methods
We propose a novel 3D object reconstruction method that recovers the desired shape from a combined multimodal representation. First, to obtain appropriate shape priors, we utilize a cross-domain retrieval method that bridges the gap between images and 3D shapes. Given the input image, this method returns 3D shapes describing structurally homologous objects. For instance, when the network receives an image of a boss chair, the retrieval method will provide 3D chairs with structures such as large backrests and wheeled five-star feet. Second, we need to utilize the retrieved 3D shapes to make up for the missing structural information of the 2D target image. We first extract the features of images and 3D shapes under the supervision of carefully designed domain-specific loss functions, which learn the image features on the individual structures and the shape features on the overall structures, respectively. Then, we adopted the cross attention mechanism to explore the potential relation between the image feature and shape prior feature, based on which they are further combined into a highly integrated feature for 3D reconstruction. Finally, we expected the integrated feature to carry the overall homologous characteristics from priors and the differentiated individual characteristics from the single-view image. Thus, we adopted the 3D shape decoder to recover the 3D structural details from the integrated feature. Note that, to meet the previously desired reconstruction effect, the whole training process is under the supervision of the loss function that examines the reconstruction performance in 3D space.
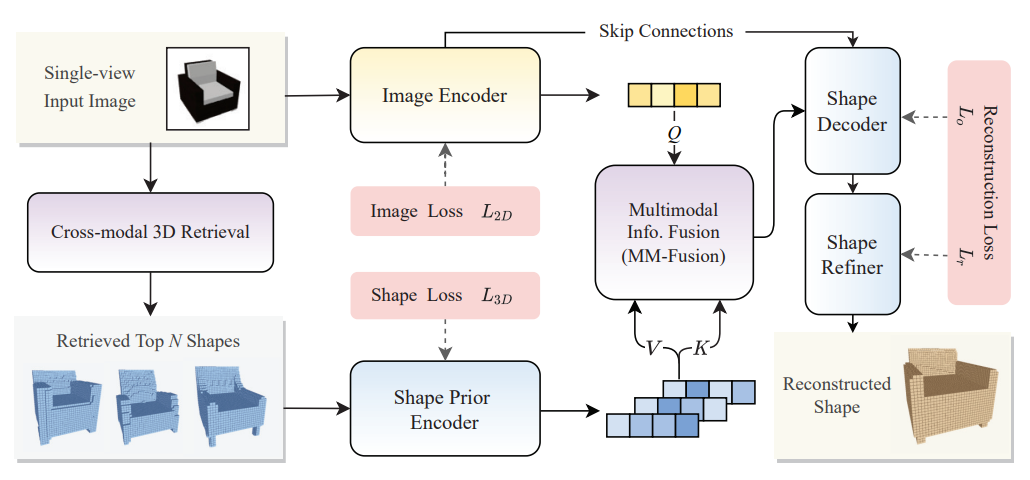
The framework of CPG3D includes three parts:
- Cross-modal prior knowledge extraction: input single-view image is used to retrieve the related 3D shape priors.
- Multimodal information learning: the loss function L2D and L3D is utilized to supervise the feature extraction of the input image and shape priors, and these extracted features are further fused by the cross-modal attention modules.
- Three-dimensional model reconstruction: The decoder is used to recover the 3D shape, and the refiner is adopted to optimize this reconstructed shape in detail.
Experiments Results
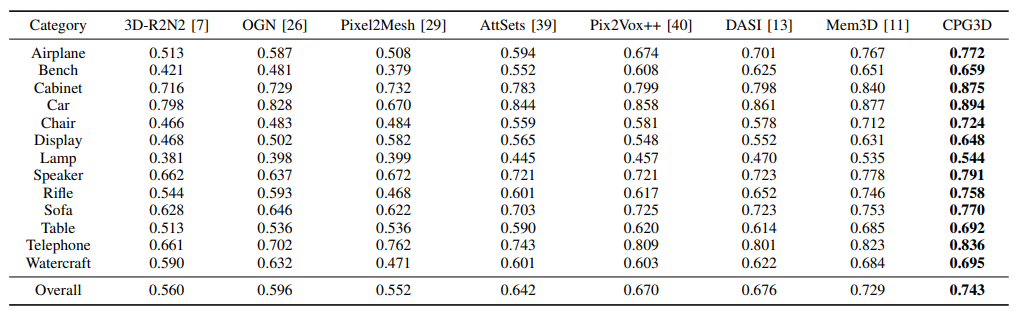
Quantitative Results
To demonstrate the performance of our approach, we compare our method with several SOTA methods on the ShapeNet dataset. To ensure a fair comparison, all methods are evaluated under the same input images for all experiments. The final experimental results are listed in Table. Higher scores of IoU and F-Score@1% indicate better reconstruction quality.

Qualitative Results
The figure shows several reconstruction examples on the ShapeNet testing set. In these examples, benefiting from the retrieved shape priors, CPG3D maintains the fundamental structures of the target shape, such as the legs of the chair and the spoiler wing of the sports car. Meanwhile, CPG3D also captures more details of the input images, for instance, the shapes of sofa armrests, holes in stool legs, and wheels of the car. Compared with the implicit surface reconstruction method DISN, our method recovers better details of the target shapes, but DISN always reconstructs smoother surfaces, which is the inborn advantage of the implicit surfaces.
Conclusion
In this paper, we proposed a novel approach for reconstructing high-quality 3D objects based on a single-view image and its related 3D shape prior knowledge. We creatively utilized the image to retrieve similar 3D shapes as prior knowledge. These retrieved priors can provide effective geometric information for 3D reconstruction. Meanwhile, we proposed a novel cross-modal integration network for the joint learning of views and priors. Subsequently, we reconstruct the object volume from integrated features and introduced skip connections to optimize the reconstruction. Experimental results demonstrated that our approach significantly improves the reconstruction quality and performs favorably against state-of-the-art methods on the ShapeNet and Pix3D datasets.